David Cordero
TvOSScribble, building Scribble for tvOS
Published on 20 Aug 2017
As I mentioned in Being a tvOS Developer, the lack of buttons on its remote control is one of the biggest challenges when creating Apps for Apple Tv.
It is sometimes quite hard to find intuitive gestures for very common actions. One of those actions is definitely the one to zap among channels.
There is basically no way to zap using a P+ or P- buttons, or a numpad, which are present in any other Tv platform, but not in Apple Tv.
Creating a Scribble for AppleTv
This was a crazy idea that I had a long time ago while speaking about the problems of Siri Remote with a colleague.
Would it not be great to have a scribble gesture recognizer as a replacement for the traditional numpad? Something similar to what we have already in the Apple Watch…
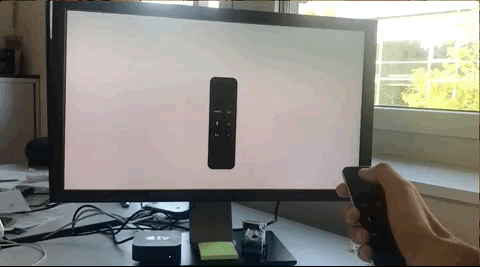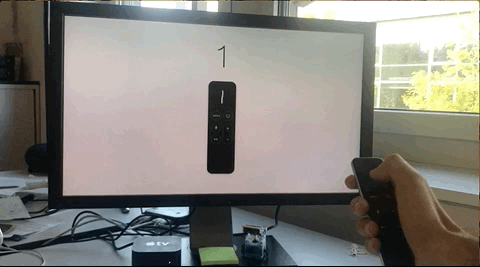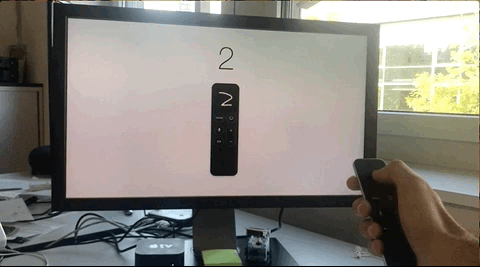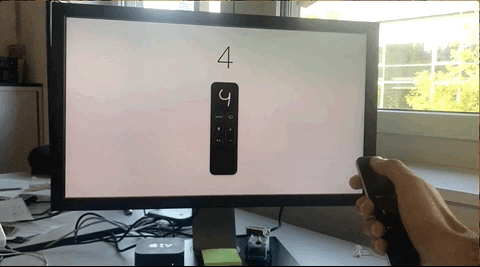
In the next days, after our conversation, I made some attempts to create a very simple prototype of this concept, failing miserably in each of them.
The biggest limitation that I found was that regardless of the real initial position of the gesture, the starting position reported by the SDK is always the center of the digitizer, this means the position (x: 960, y: 540). Subsequent swipes take values as offset from this starting point.
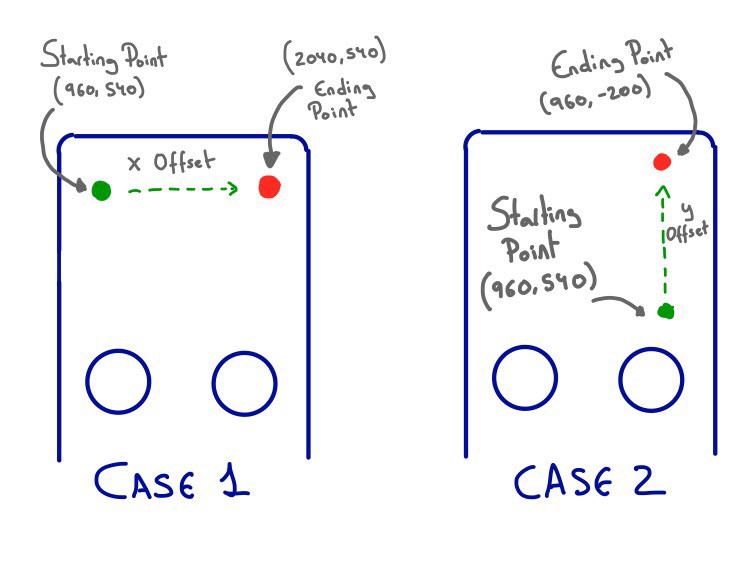
Independently of the real starting point, the SDK always reports it as 960, 540
So it can actually happen in Siri Remote that having the finger exactly in same point you get different locations from the SDK, because they depend on the sequence of the finger to reach that point… 🤕
Episode 1: Directions
Due to this limitation of the SDK, using a sequence of directions was my first attempt to solve this problem.
As the actual location of the finger is not reliable and subsequent swipes take offsets values from there, it is very easy to get the sequence of directions of the gesture. And based on those directions, to infer the result.
So if the user makes a sequence of gestures as ↗️➡️↘️⬇️↙️➡️, I could automatically infer a result of 2 and so on:
0 : “⬅️↙️⬇️↘️➡️↗️⬆️↖️⬅️” 1 : “↗️⬇️” 2 : “↗️➡️↘️⬇️↙️➡️” 3 : “↗️➡️↘️⬇️↙️➡️↘️⬇️↙️” 4 : “↙️➡️⬆️⬇️” 5 : “⬅️⬇️➡️↘️⬇️↙️⬅️” 6 : “⬅️↙️⬇️↘️➡️↗️⬆️↖️⬅️” 7 : “➡️↙️” 8 : “⬅️↙️⬇️↘️➡️↘️⬇️↙️⬅️↖️⬆️↗️➡️↗️⬆️↖️⬅️” 9 : “⬅️↙️⬇️↘️➡️➡️↗️⬆️↖️↘️⬇️↙️”
This is a very theoretical scenario which basically never happens. In the real world, there are always errors and duplicated gestures which generate a crazy sequence which will not match any of our theoretical patterns.
So I introduced some code to clean up the gesture inputs before getting the sequence of directions… things as removing the points too close to the previous one, in order to avoid wrong directions coming from the high precision of the digitizer.
And once I had a cleaned up sequence of directions, I applied Levenshtein distance to each of the patterns, getting as result the closest match.
Sounds like a really good plan right?
Well, I have to say that it was actually not :(
I worked a lot iterating this concept and the results were always really really bad, specially for the longest gestures as 6, 8 or 9.
So, I gave up…
Episode 2: CoreML
I already put this scribble idea in the drawer of failed projects, and I continued with my live as if nothing had happened :D
It was a few months later. I was in San Jose attending to the WWDC 2017, without not even thinking about that crazy idea anymore. And it was then that Mr Craig Federighi toke the stage and presented the tool that I was actually missing to create the scribble… CoreML.
At this moment, I immediately though again about the scribble, and about giving it another chance with this amazing new technology.
I had basically zero knowledge about machine learning at this time, so I started looking for more information as soon as I went back home.
I found really surprising the huge amount of crap about Machine Learning that is written out there. A lot of documentation treating this as a black box in which you put some data and you get a result back without any explanation at all about the maths behind the process.
If you are also at this point, and you want a good introduction to Machine Learning, I recommend you checking this youtube playlist by Google. In just a few videos you get a very clear guide for beginners without magic boxes.
While I was looking into all this new world, Sri Raghu with further knowledge about machine learning, was already using CoreML and he came up this great post. Computer Vision in iOS - CoreML+Keras+MNIST
As result of his post, I learned a lot and I got a very well trained CoreML model for my purpose.
But you must be wondering… what about the gestures? Was not it just impossible to get a reliable location of the fingers? How do you actually expect to get an image from there?
Well, I realised that in fact, I do not actually need an accurate initial position to get a visual representation of the path. All that I need is to track the complete sequence of points, to frame the result and to readjust the points in the path to match the new bounds. Then I can put the result in the center of and that is all…
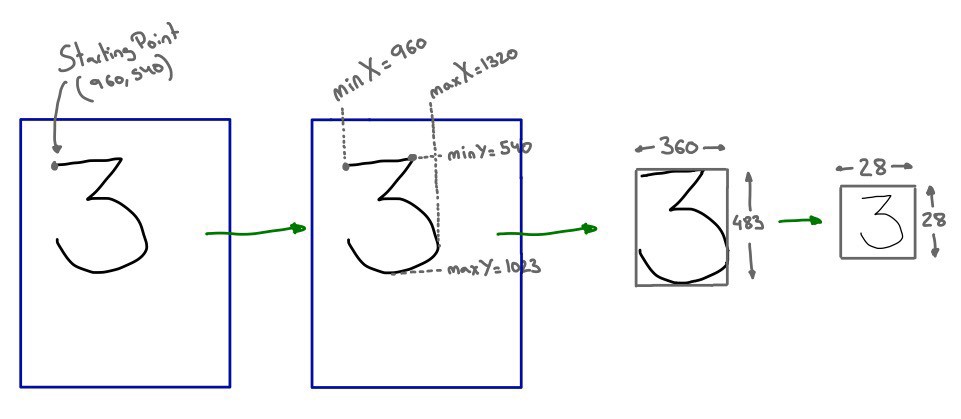
As result of the process I get a 28x28 image representation of the gesture that I can use as input for my CoreML model, finally getting a more reliable prediction 🎉
You can find the result of all this process in TvOSScribble in following link: dcordero/TvOSScribble
Feel free to follow me on github, twitter or dcordero.me if you have any further question.